Extracción de Información y Conciliación de Permisos de Circulación
Plataforma: Ubuntu 20 Tipo: Proyecto Cerrado Fecha: 2023 Enlace: No disponible
Resumen
Este proyecto tuvo como objetivo automatizar el proceso de conciliación documental asociado a permisos de circulación, permitiendo extraer, validar y consolidar información proveniente de múltiples documentos relacionados con un vehículo.
La solución fue desarrollada para una importante municipalidad de la Región Metropolitana y buscaba reducir significativamente el tiempo requerido para revisar documentación de manera manual.
El sistema fue diseñado para procesar automáticamente permisos de circulación, certificados de revisión técnica, certificados de emisiones contaminantes y seguros obligatorios (SOAP), transformando documentos escaneados en información estructurada lista para ser validada y utilizada por los usuarios.
Referencias Visuales
Documento de referencia
La siguiente imagen corresponde a un ejemplo público de un permiso de circulación utilizado únicamente con fines ilustrativos.
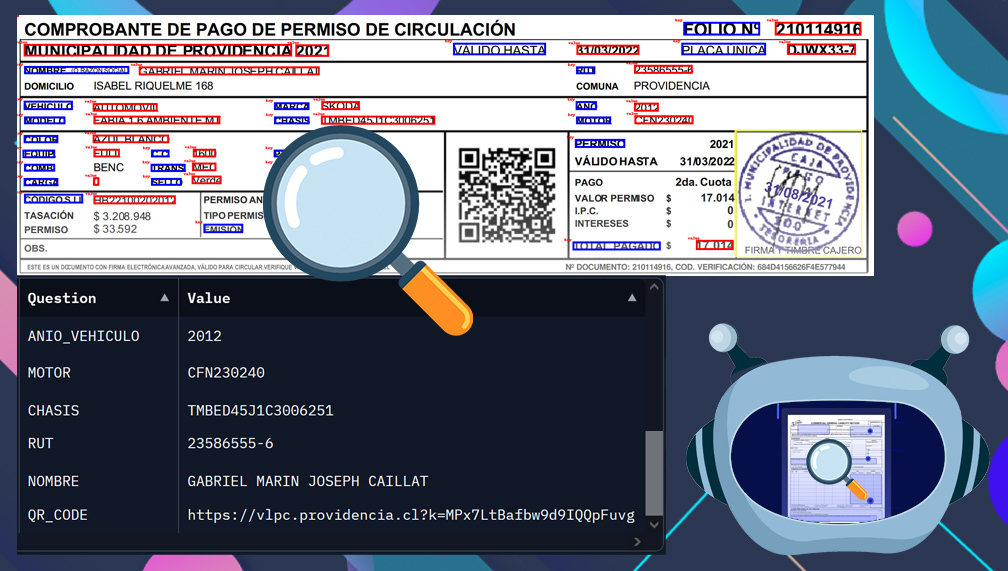
Fuente del ejemplo:
https://es.scribd.com/document/527908449/PERMISO-CIRCULACION
Contexto
Los procesos asociados a permisos de circulación suelen requerir la revisión de múltiples documentos emitidos por distintas entidades.
Antes de este proyecto, gran parte de la validación se realizaba manualmente, obligando a los usuarios a:
- Revisar documentos uno por uno.
- Verificar que los datos coincidieran.
- Detectar inconsistencias.
- Validar antecedentes complementarios.
Esto generaba una importante carga operativa y aumentaba el riesgo de errores humanos.
Problema
El desafío consistía en automatizar la conciliación de documentos asociados a un vehículo.
La solución debía ser capaz de:
- Procesar documentos escaneados.
- Separar múltiples documentos contenidos en una misma imagen.
- Identificar automáticamente el tipo documental.
- Extraer información relevante.
- Comparar datos entre documentos.
- Detectar inconsistencias.
- Integrarse con una plataforma de gestión.
Además, los documentos podían presentar distintos formatos, resoluciones y niveles de calidad, lo que agregaba complejidad al proceso.
Arquitectura General
Solución
La solución fue construida como una plataforma de procesamiento documental especializada.
Cuando un usuario cargaba una imagen o documento, el sistema ejecutaba una serie de etapas automatizadas.
1. Separación de Documentos
Uno de los problemas identificados fue que muchos usuarios enviaban múltiples documentos dentro de una misma imagen o escaneo.
Para resolverlo se implementó un detector basado en YOLOv8 capaz de localizar y recortar automáticamente cada documento individual.
Por ejemplo:
Imagen Escaneada
├── Permiso de Circulación
├── SOAP
├── Revisión Técnica
└── Certificado de Emisiones
Esto permitía que cada documento continuara por su propio flujo de procesamiento.
2. Clasificación Documental
Una vez separado cada documento, se utilizaba un modelo de clasificación para determinar automáticamente su tipo.
Para ello se entrenaron modelos específicos utilizando LayoutLMv3, permitiendo mejorar la precisión de las etapas posteriores de extracción.
Las categorías consideradas fueron:
- Permiso de circulación.
- SOAP.
- Revisión técnica.
- Certificado de emisiones contaminantes.
3. Extracción de Información
Cada tipo documental utilizaba un layout parser especializado.
Esta decisión permitió adaptar la extracción a la estructura particular de cada documento, obteniendo resultados más precisos que una estrategia genérica.
Para el reconocimiento de texto se utilizó Tesseract OCR, seleccionado tras evaluar distintas alternativas disponibles en ese momento.
4. Conciliación
Una vez obtenida la información estructurada, el sistema realizaba validaciones cruzadas entre documentos.
Entre los datos conciliados se encontraban:
- Patente.
- Propietario.
- Identificación del vehículo.
- Vigencias.
- Información técnica.
La conciliación permitía detectar inconsistencias y reducir la necesidad de validaciones manuales.
Validación mediante Código QR
Como parte del flujo documental se incorporó detección de códigos QR presentes en algunos documentos.
La efectividad de esta etapa dependía fuertemente de la calidad de los escaneos recibidos.
En algunos casos los documentos presentaban:
- Baja resolución.
- Compresión excesiva.
- Fotografías tomadas desde dispositivos móviles.
- Escaneos parciales.
Estas condiciones dificultaban la lectura consistente de los códigos.
La experiencia confirmó una lección recurrente en proyectos de OCR: la calidad del documento de entrada suele ser uno de los factores más determinantes en el resultado final.
Mi Participación
Participé como líder técnico del proyecto.
Mis responsabilidades incluyeron:
- Diseño de la arquitectura general.
- Coordinación del equipo de trabajo.
- Definición de metodología de desarrollo.
- Diseño del pipeline documental.
- Entrenamiento de modelos.
- Definición de layouts documentales.
- Integración de OCR.
- Supervisión de la creación de datasets.
- Presentación de resultados al cliente.
La gestión del proyecto se apoyó principalmente en metodologías Kanban complementadas con prácticas de SCRUM para seguimiento y coordinación.
Flujo Operacional
Desafíos Técnicos
Documentos Múltiples
Muchos documentos llegaban agrupados dentro de una misma imagen, lo que obligó a desarrollar una etapa previa de separación automática.
Variabilidad de Formatos
Cada documento poseía una estructura diferente, por lo que fue necesario construir layouts específicos para cada categoría.
Calidad de Escaneo
La calidad de los documentos recibidos variaba considerablemente, afectando tanto OCR como detección de códigos QR.
Restricciones de Infraestructura
La solución debía operar dentro de restricciones presupuestarias y de infraestructura.
Aunque existían alternativas que podían acelerar aún más el procesamiento utilizando hardware especializado, se priorizó una arquitectura que equilibrara rendimiento, costos operacionales y escalabilidad.
Tecnologías Utilizadas
- Python
- Ubuntu 20
- PostgreSQL
- YOLOv8
- LayoutLMv3
- Tesseract OCR
- Layout Parser
- Procesamiento Documental
- Computer Vision
- Kanban
- SCRUM
Resultados
Durante las pruebas realizadas, el tiempo requerido para procesar documentación se redujo aproximadamente a un tercio del proceso manual utilizado previamente.
Entre los resultados obtenidos destacan:
- Separación automática de documentos.
- Clasificación documental automática.
- Extracción estructurada de información.
- Conciliación automática de antecedentes.
- Reducción de errores manuales.
- Integración con plataforma de gestión.
- Capacidad de crecimiento mediante incorporación de nuevos documentos.
Impacto
El proyecto permitió transformar procesos manuales basados en revisión documental en un flujo automatizado de análisis y conciliación.
La solución redujo tiempos operacionales, disminuyó errores asociados a digitación manual y proporcionó una base tecnológica preparada para futuras mejoras y adaptaciones normativas.
Lo que Aprendí
Este proyecto reforzó mi especialización en procesamiento documental y extracción automatizada de información.
También me permitió liderar un equipo multidisciplinario y comprobar que una solución de Document AI no depende únicamente de OCR, sino de la correcta integración de múltiples componentes:
- Detección.
- Clasificación.
- Layout Parsing.
- OCR.
- Validación.
- Conciliación.
La experiencia también reforzó una lección importante en proyectos de inteligencia artificial: la calidad de los resultados depende tanto de los modelos utilizados como de la calidad y estructura de los datos disponibles.
Viéndolo en Retrospectiva
Mirando el proyecto años después, considero que fue una de mis primeras experiencias construyendo una solución integral de Document AI.
Más allá de la extracción de texto, el verdadero desafío consistió en diseñar un sistema capaz de comprender distintos tipos documentales, validar información cruzada y transformarla en datos estructurados útiles para los usuarios.
Este proyecto representa una etapa importante en mi evolución profesional hacia soluciones especializadas en procesamiento documental, OCR avanzado y automatización de flujos de información.